High Availability
High Availability (HA) is an approach to infrastructure design focusing on reducing downtime and eliminating single points of failure.
An HA infrastructure ensures systems, applications, and databases are active when other components in the infrastructure fail. For example, a load balancer with failover that redistributes traffic to a redundant Droplet after a first Droplet fails is considered an HA infrastructure since it ensures that at least one server remains available.
App Platform
Load balancers handle incoming requests in App Platform. Load balancers evenly distribute incoming requests across all containers that pass a health check and provide capacity to your service. Distributing requests this way is what enables your service’s high availability.
High availability (HA) is only supported for Professional apps when running two or more containers so that there is a failover for App Platform’s load balancer to use. If you require HA when using Starter or Basic apps, you must upgrade your app to the Professional tier.
MongoDB
MongoDB offers high availability through replica sets. Replica sets have secondaries, with the same data as the primaries, that can replace the primary if it fails or becomes unavailable.
For more information on how to set up failover, see How to Configure a MongoDB Replica Set on Ubuntu 20.04.
MySQL
MySQL clusters consist of one or more management nodes (ndb_mgmd) that can manage the cluster’s configuration and control the data nodes (ndbd). To learn more about multi-node configuration, see How to Create a Multi-Node MySQL Cluster.
MySQL also has a high availability option which focuses on meeting uptime requirements and reduce data loss. You created three instances of the MySQL database when you enable high availability which are backups to the primary system.
PostgreSQL
PostgreSQL uses replication which makes PostgreSQL databases highly available. Replication is the process of copying data from one PostgreSQL server to another. The primary server is the main server while the replicas are replica servers. In case the primary server fails or becomes unavailable, there is a replica server that can take the primary server’s place.
Replication reduces downtime of a PostgreSQL database.
Redis
Redis has failover commands that allows the cluster to be highly available. The main node has replicas ready to replace the main node in case the main node becomes unavailable.
Kubernetes
Kubernetes clusters require a balance of resources in both pods and nodes to maintain high availability and scalability. To further ensure high availability, node pools with production workloads should have at least three nodes. This gives the cluster more flexibility to distribute and schedule work on other nodes if a node becomes unavailable. Learn more about the best practices, see Kubernetes Best Practices.
If you enable high availability for a cluster, you can create multiple replicas of each control plane component, ensuring that a redundant replica is available when a failure occurs. This results in additional increased uptime. DigitalOcean provides a 99.95% uptime SLA for control planes when high availability enabled. Learn more about SLA, see DigitalOcean Kubernetes Service Level Agreement (SLA).
Load Balancers
We automatically monitor DigitalOcean Load Balancers and ensure, through health checks, that only healthy Droplets can receive requests. By monitoring load balancers and Droplets’ health checks, we ensure high availability.
Additionally, DigitalOcean Load Balancers with more nodes can stay more highly available by distributing traffic among the remaining nodes when a node goes down.
Reserved IP
Reserved IPs allow you to reassign an IP address from one Droplet to another when a Droplet fails which makes reserved IPs a highly-available infrastructure. Reserved IP could also be assign to a load balancer that has active failover, as illustrated below. This can ensure that your application’s traffic remains flowing through the same IP address without disruption.
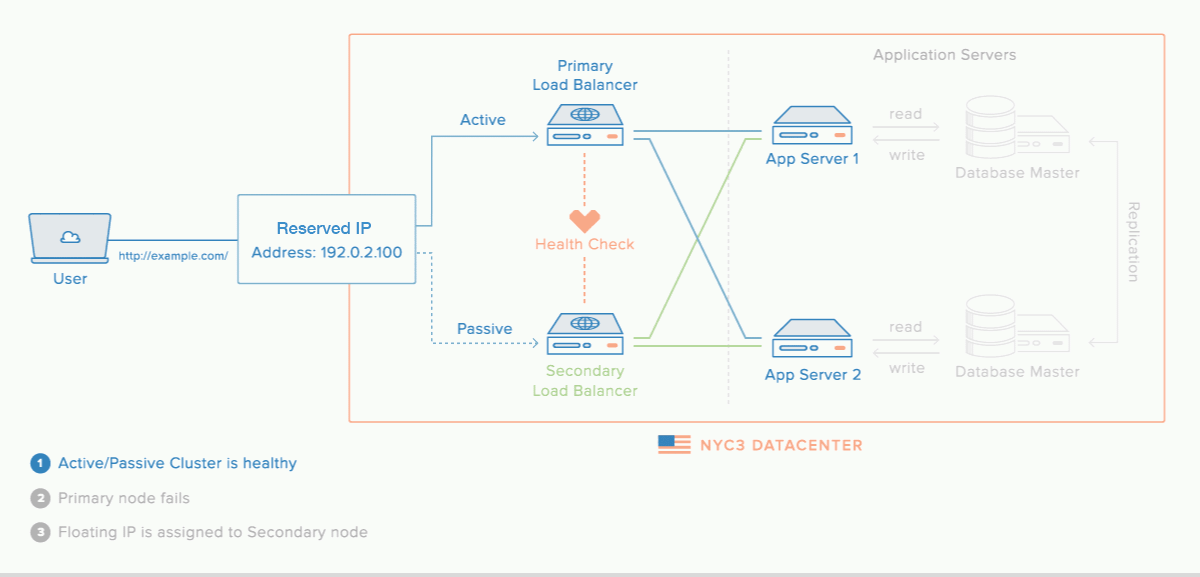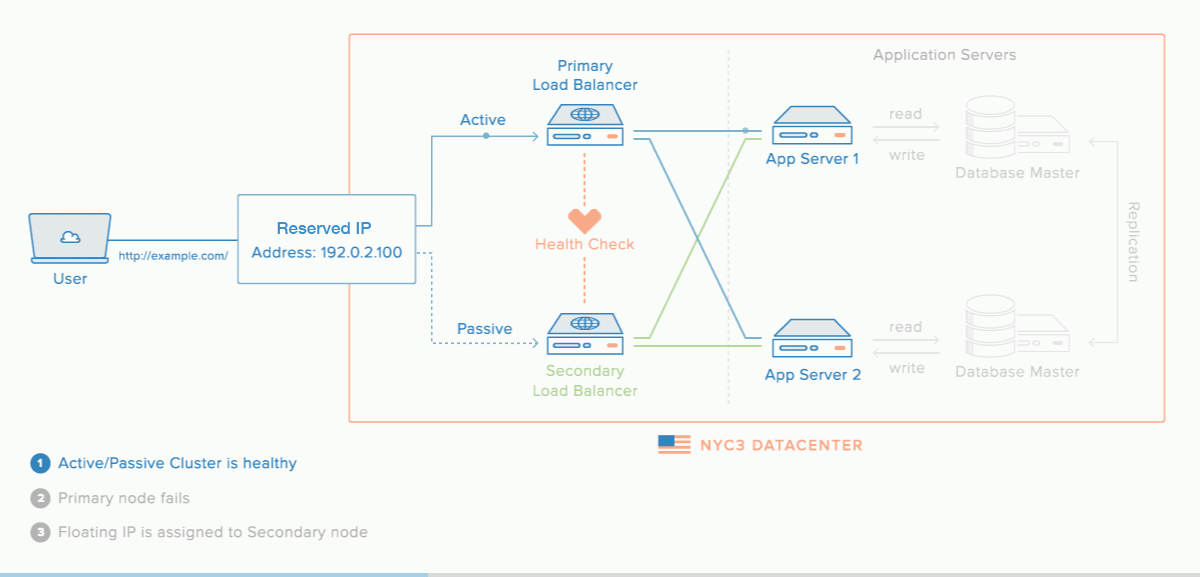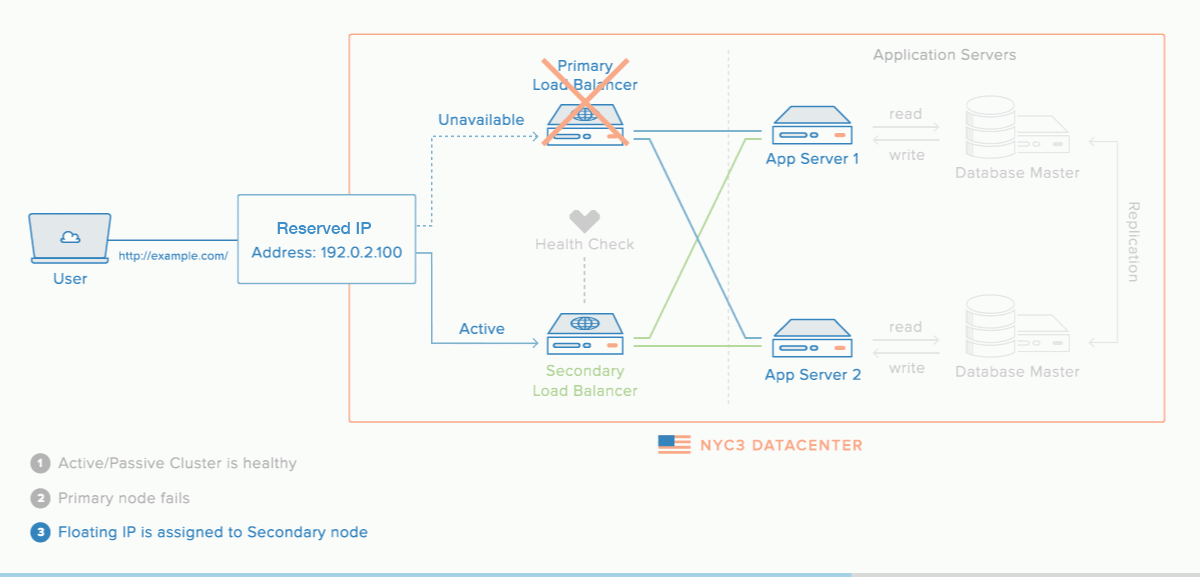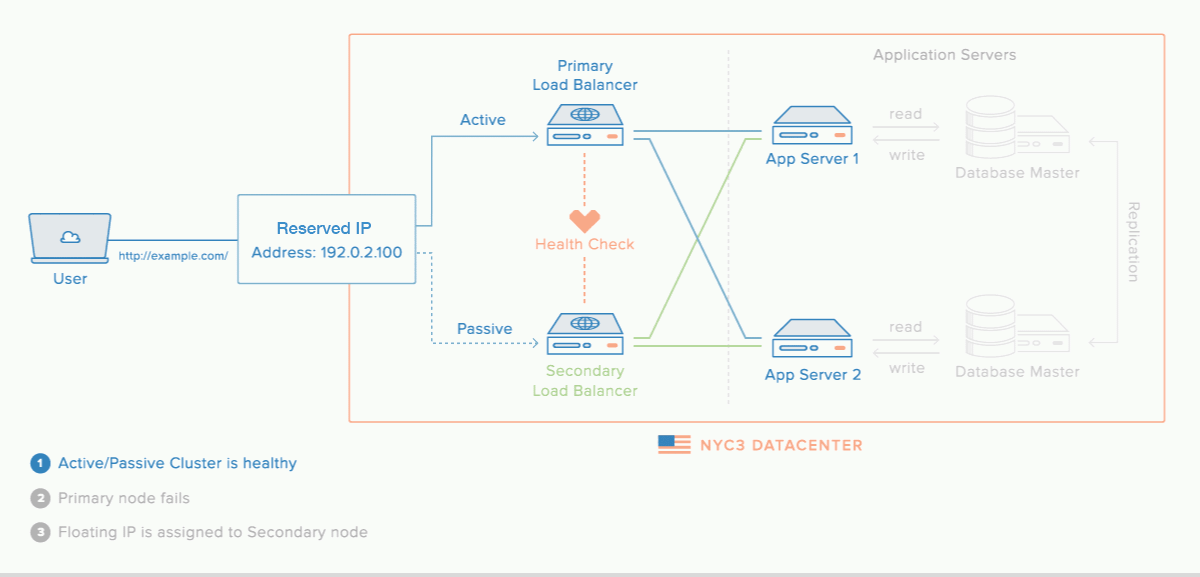
Spaces
Spaces uses Ceph to ensure high availability. In the case of data loss or component failure, it allows Spaces to continue service without interruption.
Additionally, Spaces uses different monitoring systems built around tools including Icinga, Prometheus, and our own open-source ceph_exporter. These help us respond immediately to any issues with our Ceph infrastructure to ensure continuous availability.
Ceph is also compatible with a large subset of the S3 RESTful API, including useful tools and commands.