Operations Throughput Metric
Operations throughput metric is a measurement of throughput of fetch, insert, update, and delete operations across all databases on the server.
MySQL
The operations throughput plot displays the rate of fetch, insert, update and delete operations per second across all databases (schemas) on the main server.
The throughput plot shows the rate of fetches, inserts, updates, and deletes in rows per second.
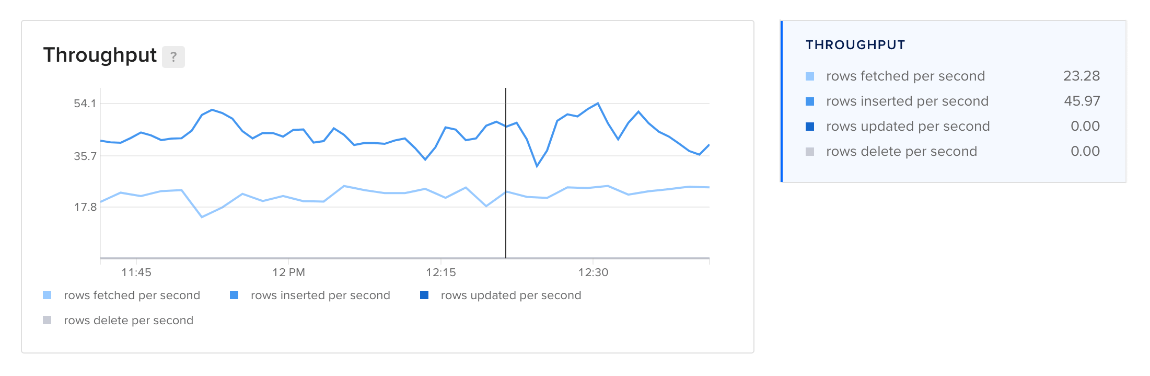
If you observe bottlenecks, look for slow queries in the query statistics on the Logs & Queries page, then use the EXPLAIN statement to explore opportunities for query optimization.
For more information on monitoring MySQL clusters, see How to Monitor MySQL Database Performance.
PostgreSQL
The throughput plot records the rate of row fetches, row inserts, row updates, and row deletes across all user tables in the database. Monitoring the overall usage pattern is useful for making tuning decisions and identifying potential problems. For example, unexpected changes in usage patterns could indicate a newly introduced bug or security breach.
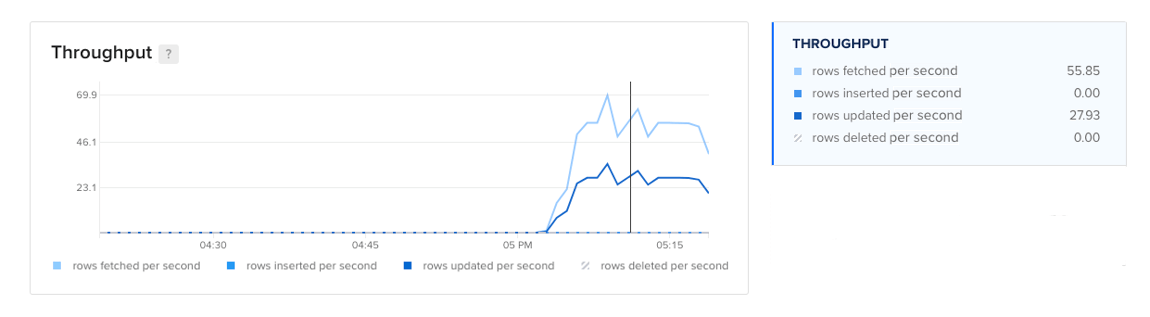
This data is also useful for understanding how efficiently your database handles each type of operation and identifying opportunities to improve performance through tuning, design modifications, and scaling. For example, while indexes are helpful for improving performance in read-heavy use cases, they can slow down insert, update and delete (DML) operations.
For more information on monitoring PostgreSQL clusters, see How to Monitor PostgreSQL Database Performance.
Redis
The throughput plot displays the overall rate of all Redis operations on the main server, expressed as a moving average of operations per second.
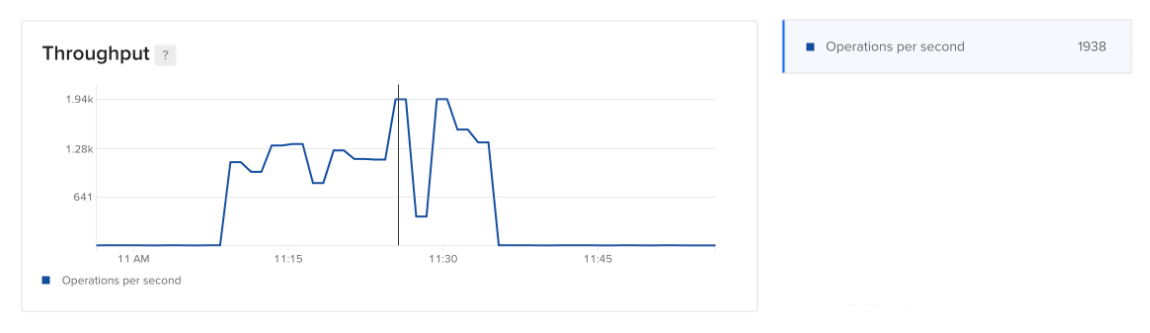
You can compare this plot with node performance metrics to identify potential resource constraints. For more insights, look at the query statistics on the Logs & Queries page.
For more information on monitoring Redis clusters, see How to Monitor Redis Database Cluster Performance.