Notebooks are a web-based Jupyter IDE with shared persistent storage for long-term development and inter-notebook collaboration, backed by accelerated compute.
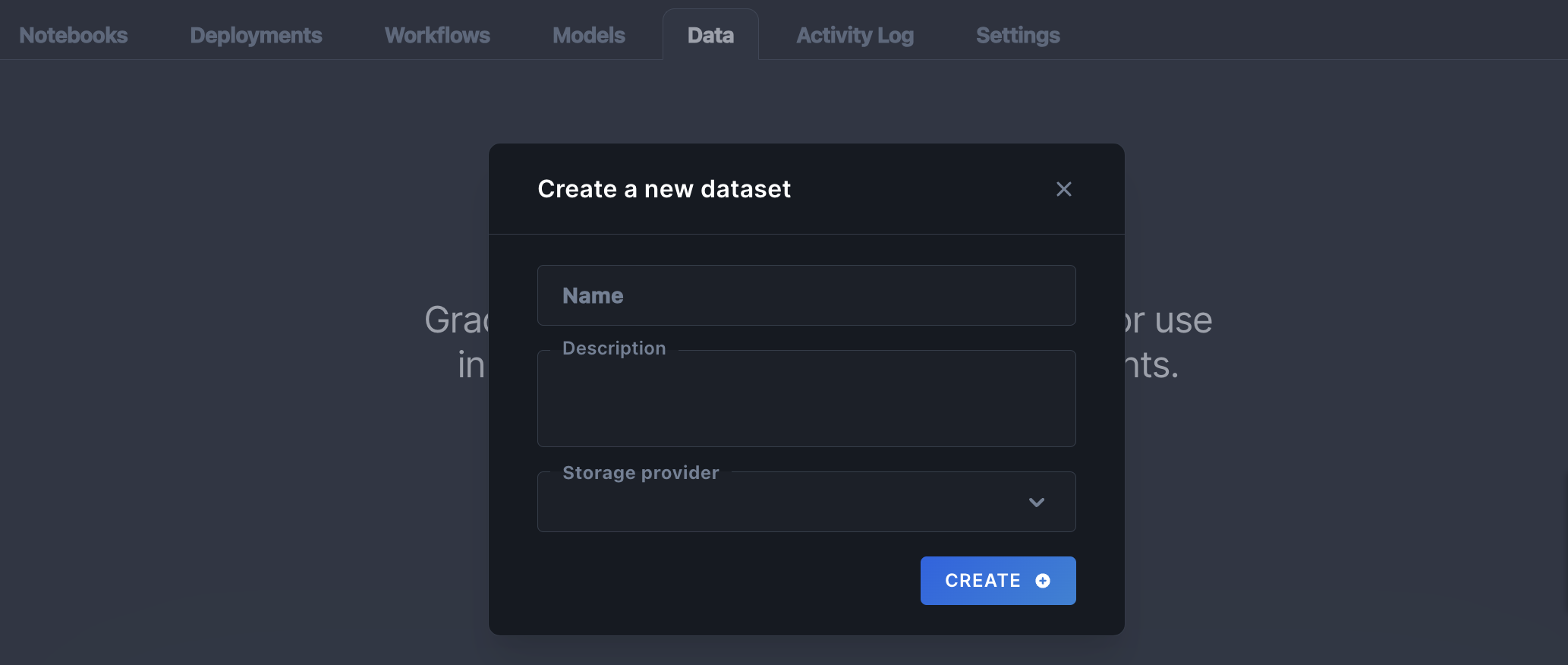
To create a new dataset, select the Data tab in a project and click Create a Dataset. In the Create a new dataset window, specify a name, an optional description, and a storage provider.
If the team already has datasets, click Add to create a new dataset. On the next screen, you can drag and drop or upload your files and then click Upload.
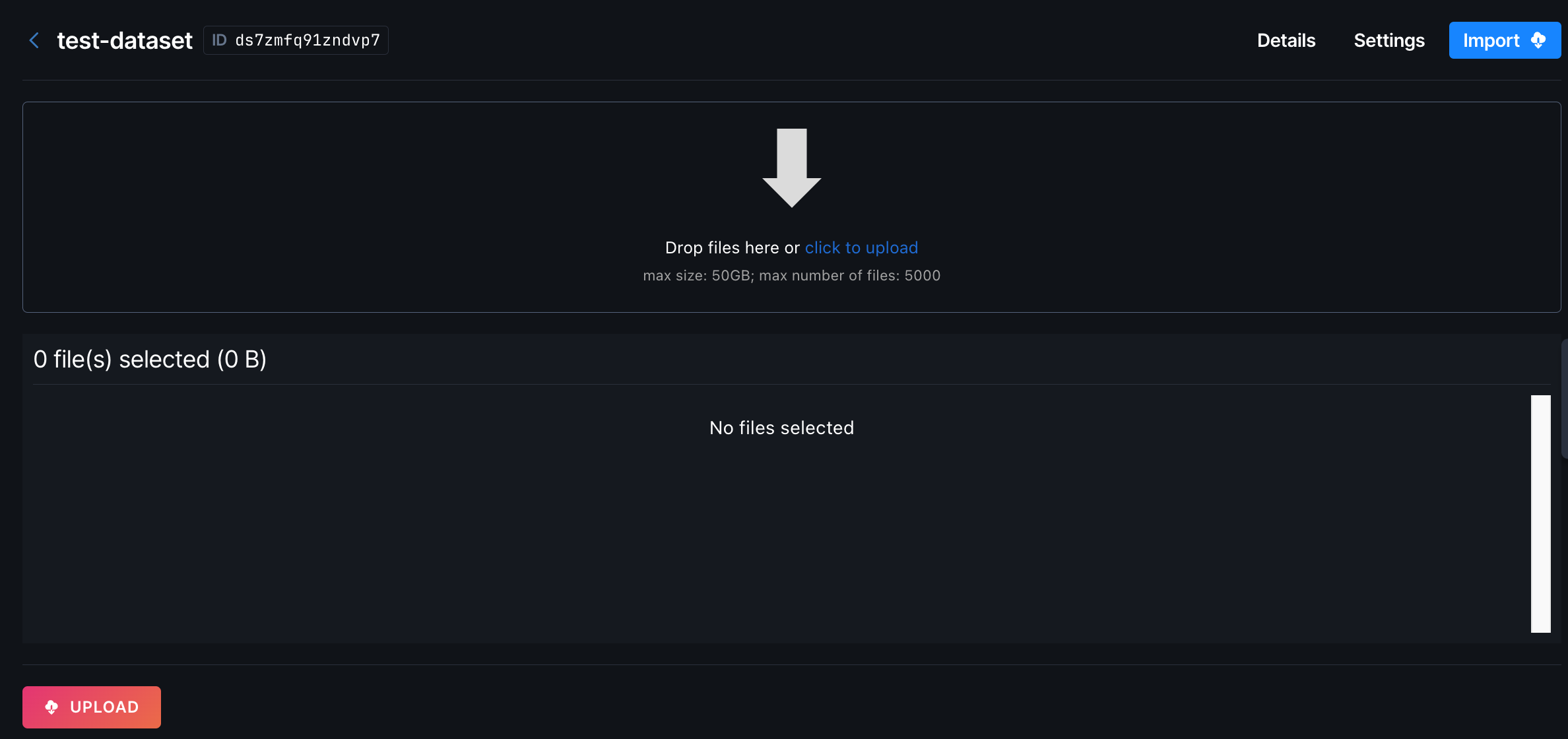
Note the ID of the dataset to use elsewhere.
You can also create a dataset in a notebook as described in Connect Data Sources.
To create a new dataset that does not yet have an ID in the CLI, use the gradient datasets create command:
$ gradient datasets create --name democli --<storage-provider-id> ssfe843ndkjdsnr
The output looks similar to the following:
Created dataset: dsr5zdx0thjhfe2
All Gradient datasets are versioned. To make any changes to data in a dataset, first you need to create a new version of the dataset. Use the following command, replacing <dataset-id> with the ID of the dataset you want to update:
$ gradient datasets versions create --id <dataset-id>
Once the version is created, you can then add files to the dataset version.
$ gradient datasets files put --id dst364npcw6ccok:fo5rp4m --source-path ./some-data/
Once all desired files are uploaded to the version, commit the version to the dataset.
$ gradient datasets versions commit --id dst364npcw6ccok:fo5rp4m
Once the dataset version is committed, the data is available in the Paperspace console for you to reference in Notebooks, Workflows, and Deployments.
To view a list of all datasets, use one of the following commands:
gradient datasets list
The output looks similar to the following:
+------+-----------------+-------------------------+
| Name | ID | Storage Provider |
+------+-----------------+-------------------------+
| test | dst364npcw6ccok | test1 (splgct3arqdh77c) |
+------+-----------------+-------------------------+
gradient datasets details --id <dataset-id>
The output looks similar to the following:
+-----------------+-------------------------+
| Name | test |
+-----------------+-------------------------+
| ID | dst364npcw6ccok |
| Description | |
| StorageProvider | test1 (splgct3arqdh77c) |
+-----------------+-------------------------+
To view dataset files, use one of the following command:
$ gradient datasets files list --id <dataset-id>
The output looks similar to the following:
+-----------+------+
| Name | Size |
+-----------+------+
| hello.txt | 12 |
+-----------+------+